Lab 12 - Deep Reinforcement Learning 1
Lab. 12 - Deep Reinforcement Learning cz. 1

1. Deep Q-Learning
Deep Q-learning (DQN) rozszerza Q-learning, używając głębokiej sieci neuronowej do przybliżania funkcji Q. Głęboka sieć neuronowa przyjmuje stan otoczenia jako dane wejściowe i generuje wartości Q dla każdej możliwej akcji. Dzięki temu model może obsługiwać złożone przestrzenie stanów o wysokich wymiarach, co sprawia, że jest odpowiedni do zadań takich jak granie w gry wideo czy sterowanie robotami.
Kluczowe elementy Deep Q-learning
Powtórka doświadczeń: W celu ustabilizowania i poprawy procesu uczenia DQN używa powtórki doświadczeń (experience replay). Zamiast aktualizować sieć Q przy każdym nowym doświadczeniu, agent przechowuje doświadczenia (zawierające aktualny stan, podjętą akcję, otrzymaną nagrodę i następny stan) w buforze powtórki (replay buffer). Podczas treningu losowe serie doświadczeń są pobierane z tego bufora w celu aktualizacji sieci. Pomaga to przerwać temporalną korelację między kolejnymi doświadczeniami, co czyni uczenie bardziej stabilnym.
Dwie sieci: Aby poradzić sobie z problemem poruszających się celów podczas uczenia, Deep Q-learning używa dwóch oddzielnych sieci: sieci Q Policy i sieci Q Target. Sieć Q Target to opóźniona kopia sieci Q Policy.
Okresowa synchronizacja - co pewną liczbę kroków, sieć Q Target jest synchronizowana z siecią Q Policy, aby jej parametry odpowiadały parametrom sieci Q Policy. Stabilizuje to proces treningu, zapewniając stały cel dla wartości Q.
2. Cel zajęć
Celem zajęć jest poznanie podstaw metod głębokiego uczenia ze wzmocnieniem na przykładzie DQN.
3. Przygotowanie środowiska
Na dzisiejszych zajęciach nie będziemy wykorzystywać ROSa. W ramach przygotowania środowiska należy jedynie zainstalować bibliotekę PyTorch w odpowiedniej wersji (w zależności od posiadania GPU lub wyłącznie CPU). Instrukcja instalacji jest dostępna tutaj.
Konieczna będzie także instalacja biblioteki gymnasium:
pip install gymnasium
Aktualnie zainstalowaną wersję torcha można sprawdzić:
import torch
print(torch.__version__)Fakt możliwości używania GPU w PyTorch można sprawdzić:
import torch
torch.cuda.is_available()4. Kroki implementacji DQN
Implementację DQN można przybliżyć do następujących kroków:
- Utworzenie sieci Policy.
- Utworzenie kopii sieci Policy jako Target.
- Wykonanie akcji przez agenta.
- Zapisanie doświadczenia do replay buffera.
- Odtworzenie próbek z replay buffera.
- Wywołanie sieci Policy na podstawie aktualnego stanu.
- Wywołanie sieci Target na podstawie aktualnego stanu.
- Obliczenie wartości Q dla stanu i wykonanej akcji (z kroku 3).
- Poprawa wyjść z sieci Target na podstawie wartości obliczonej w kroku 8.
- Dokonanie treningu sieci Policy wykorzystując zaktualizowane wyjścia sieci Target.
- Powtórzyć kroki 3-10 określoną liczbę razy.
- Przeprowadzić synchronizację.
- Powrócić do kroku 3.
Prawdopodobnie aktualnie są one mało zrozumiałe, ale mogą okazać się pomocne podczas analizy przykładowej implementacji w dalszej części instrukcji.
5. Przykładowa implementacja
Przykładową implementację dla środowiska Frozen Lake v1 można znaleźć tutaj.
Schemat powyższej sieci dla przykładowego stanu (0, lewy górny róg) i przykładowych wyjść:
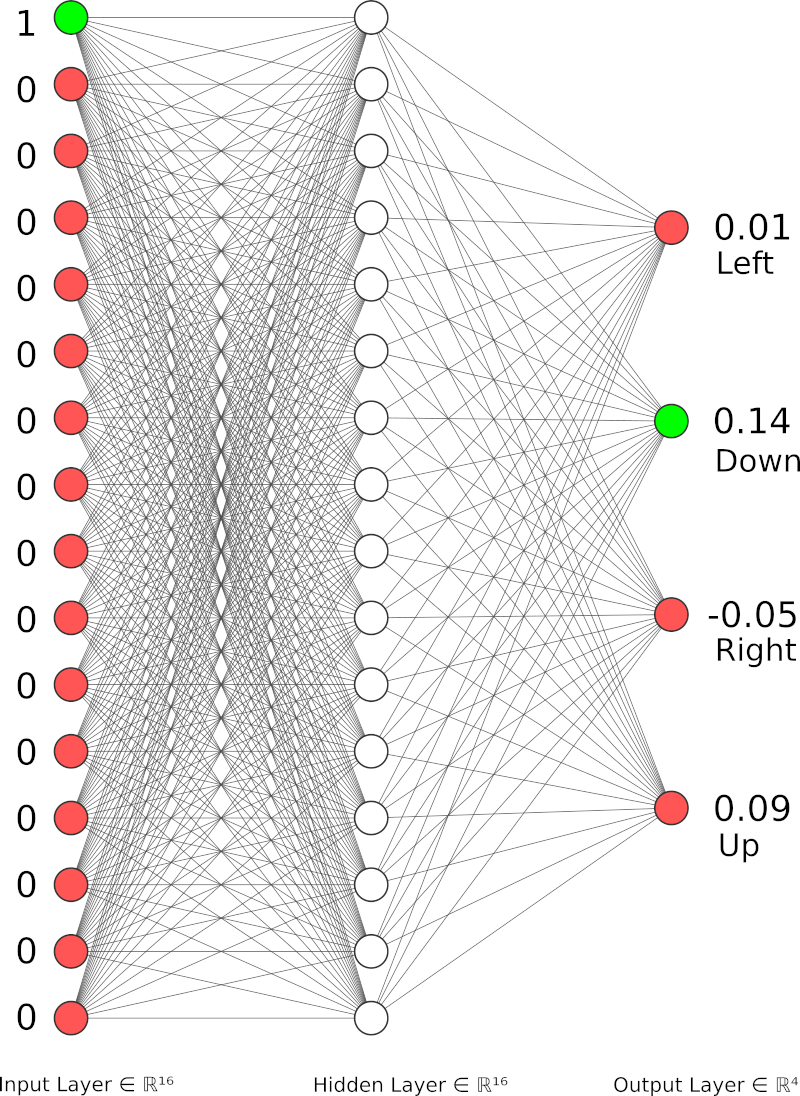
Stan przedstawiamy w systemie one-hot (tylko aktualny stan jest jedynką, reszta jest zerami), akcja jest wybierana na podstawie najwyższej wartości na wyjściu (w tym przykładzie największą wartość ma akcja o indeksie 1, czyli "Down").
Można ją pobrać korzystając z:
wget https://raw.githubusercontent.com/kamilmlodzikowski/LabARM/main/Lab12-DQN1/frozen_lake_dqn.py
W przypadku osób z urządzeniami wyposażonymi wyłącznie w CPU nie ma konieczności zmiany domyślnego device dla torch, w przypadku GPU należy zmienić linijkę:
torch.set_default_device('cpu')na
torch.set_default_device('cuda')W przypadku błędów z Qt należy dodać:
import os
os.environ.pop("QT_QPA_PLATFORM_PLUGIN_PATH")5.1 Analiza implementacji
Proszę przeanalizować podaną powyżej implementację (uruchomić) i dodać komentarze oznaczające kolejne kroki z punktu 4 w odpowiednich miejscach, np.:
# KROK 1
policy_dqn = DQN(in_states=num_states, h1_nodes=num_states, out_actions=num_actions) 5.2 Wpływ parametrów i rozmiaru sieci
Skuteczność sieci można obserwować na wykresie tworzonym i zapisywanym po treningu (frozen_lake_dql.png). Wykres po lewej przedstawia średnią liczbę nagród na epizod, wykres po prawej parametr epsilon dla epizodu.
Wpływ parametrów dobrze początkowo badać na wyłączonym ślizgu (is_slippery=False), dopiero w przypadku sensownego kandydata załączać i sprawdzać czy trend się utrzymuje w przypadku niedeterministycznego środowiska.
Proszę zbadać wpływ niżej wymienionych parametrów na działanie sieci:
learning_rate_adiscount_factor_gnetwork_sync_ratereplay_memory_sizemini_batch_size- kształt funkcji epsilon (np. funkcja wykładniczo malejąca)
- liczba
episodesdla treningu
Jak wygląda skuteczność sieci w przypadku dodania nowych warstw? Co przy jednoczesnym zwiększeniu liczby epizodów?
6. Zadanie do samodzielnej realizacji
W ramach pracy samodzielnej proszę o:
- dodanie komentarzy do oryginalnej implementacji tak jak opisano w punkcie 5.1,
- opisanie wpływu parametrów oraz struktury sieci tak jak opisano w punkcie 5.2,
- ze strony Gymnasium proszę wybrać dowolne środowisko (inne niż Frozen Lake) i zmodyfikować kod tak, aby był w stanie działać z tym środowiskiem (zakładka
ENVIRONMENTS). Sugeruję wybór czegoś zClassic ControllubToy Text. Parametry tutaj nie muszą być dostrojone idealnie, ale chociaż częściowo powinno być możliwe wyuczenie sieci.
Na eKursy należy przesłać:
- oryginalny kod z komentarzami dotyczącymi kroków (plik .txt)
- opis wpływu parametrów i rozmiaru sieci (tekstowo online lub plik .txt)
- zmodyfikowany kod działający dla innego środowiska (plik .txt)
Materiały dodatkowe
Autor: Kamil Młodzikowski
W oparciu o: link.