Lab 06 - Czyszczenie danych
Lab 05 - Czyszczenie danych
Celem czyszczenia danych jest:
- wykrycie elementów brakujących i ich uzupełnienie lub usunięcie wierszy
- konwersja danych (np daty) i typów nominalnych (w tym korekta błędów w nazwach elementów, np. poznań, Poznan, Pznan, Poznań)
- analiza rozkładów i usunięcie elementów odstających (outlierów) (Lab 06)
- normalizacja danych i normalizacja rozkładu (Lab 06)
Zbiór danych
W zadaniach będziemy posługiwać się zbiorem opisującym historię sprzedaży budynków, zawierającym szczegóły dotyczące nieruchomości oraz cenę za jaką zostały sprzedane: melb_data.csv.
Ocena efektów - skuteczność klasyfikacji
W zadaniach spróbuj odnieść efekty wprowadzonych zmian do efektu dla zadania klasyfikacji. Do oceny zastosuj funkcję:
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
def score_dataset(x_train, x_valid, y_train, y_valid):
model = RandomForestRegressor(n_estimators=100, random_state=0)
model.fit(x_train, y_train)
preds = model.predict(x_valid)
return mean_absolute_error(y_valid, preds)Do oceny skuteczności klasyfikacji stosuj zawsze zbiór uczący i testowy, tzn. wszelkie hipotezy, wyznaczanie statystyk (np. wartości średniej, kwartyli) wyznaczaj wyłącznie dla zbioru uczącego, a następnie metodę zastosuj dla zbioru testowego (bez zmiany wartości wyznaczonych parametrów). Podział na zbiór uczący i testowego przeprowadź w proporcji 70/30%. Podział na zbiory przeprowadź na początku i potem używaj tych zbiorów dla wszystkich danych (rozwiązanie to zawiera pewien błąd metodyczny wynikający z wielokrotnego wykorzystania tego samego zbioru, zajmiemy się tym na Lab 07).
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
train_df, test_df = train_test_split(df, test_size=0.7)
# czyszczenie danych
# train_df_cleaned = ...
# test_df_cleaned = ...
cols_x = train_df_cleaned.select_dtypes(include=[np.number]).columns.difference(['Price']) # wybiera tylko kolumny z wartosciami numerycznymi, za wyjątkiem kolumny z wartością referencyjną - wejście do klasyfikatora
cols_y = 'Price' # - wyjście z klasyfikatora
print(score_dataset(train_df_cleaned[cols_x], test_df_cleaned[cols_x], train_df_cleaned[cols_y], test_df_cleaned[cols_y]))UWAGA
- Funkcja
score_datasetzwraca średnią z wartości bezwzględnej błędu dla zbioru testowego. - Do oceny skuteczności stosujemy zbiór testowy, który nie został użyty w procedurze uczenia i wyboru metody.
- Pamiętaj jednak, że jednoznaczna interpretacja tego czy różnica między oboma podejściami jest istotna statystycznie wymaga rozszerzonej analizy, zajmiemy się tym na Lab 07.
- Porównując otrzymany wynik błędu spróbuj określić dlaczego nastąpiła zmiana, pamiętaj przy tym, że podejście związane z czyszczeniem danych zależy od typu danych.
Elementy brakujące
- Wczytaj zbiór danych z pliku do zmiennej
df - Wyznacz liczbę wartości brakujących (pustych) i przeanalizuj w jakich kolumnach występują braki
missing_values_count = df.isnull().sum()- Spróbuj określić dla każdej kolumny procent występowania wartości brakujących. Wyświetl je w postaci tabeli, gdzie indeksem jest nazwa kolumny, a kolumnami procent braków oraz całkowita liczba braków (możesz użyć metody
pd.concat)
Podejście 1: usunięcie kolumn/wierszy zawierających przynajmniej 1 element pusty - przetestuj oba podejścia:
df_cleaned_rows = df_set.dropna()
df_cleaned_cols = df_set.dropna(axis=1)- Zastanów się, które z tych podejść powinno być zastosowane jeśli chcemy stworzyć klasyfikator predykujący ceny nieruchomości?
- Czy wiesz, które wiersze zostały usunięte? Spróbuj wyodrębnić listę ich indeksów.
- Sprawdź dokumentację dropna i zobacz:
- w jaki sposób usunąć tylko wiersze z jeśli wartości puste są w kolumnie
BuildingArea, - ograniczając liczbę wierszy sprawdź ile zostanie wierszy jeśli usunie się wiersze, które nie mają równocześnie wypełnionego pola
BuildingAreaiYearBuilt
- w jaki sposób usunąć tylko wiersze z jeśli wartości puste są w kolumnie
Podejście 2: wypełnienie pustych wartości np. zerami lub wartością, która poprzedza wartość brakującą
df_cleaned_zeros = df.fillna(0) # wypełnia zerami
df_cleaned_bfill = df.fillna(method='bfill', axis=0).fillna(0) # wypełnia wartością poprzedzającą z danej kolumny, jeśli to niemożliwe, wstawia 0- Zastanów się kiedy takie podejście może być stosowane, czy można je użyć do klasyfikacji?, sprawdź w dokumentacji fillna jakie są jeszcze możliwości wypełnienia wypełnienia?
- Kiedy wypełnianie wartością sąsiednią ma sens? Jeśli stosujemy je do klasyfikacji to jaką strategię przyjąć w odniesieniu do brakujących wartości referencyjnych (jest to wartość, która ma być predykowana przez klasyfikator) a jaką w odniesieniu do brakujących cech (wartość/wartości, które są wejściem klasyfikatora)?
Podejście 3: podstawienie wartości średniej/mediany/mody:
from sklearn.impute import SimpleImputer
imp_mean = SimpleImputer(missing_values=np.nan, strategy='mean')
df_train_numeric = train_df.select_dtypes(include=[np.number]).copy()
df_test_numeric = test_df.select_dtypes(include=[np.number]).copy()#wybór tylko kolumn przechowujacych liczby, należy wykonać kopię obiektu
df_train_numeric.loc[:] = imp_mean.fit_transform(df_train_numeric) # dopasowanie parametrów (średnich) i transformacja zbioru uczącego
df_test_numeric[:] = imp_mean.transform(df_test_numeric) # zastosowanie modelu do transformacji zbioru testowego (bez wyznaczania parametrów)- Kiedy wypełnianie wartością średnią/medianą ma sens? Jeśli stosujemy je do klasyfikacji to jaką strategię przyjąć w odniesieniu do brakujących wartości referencyjnych (jest to wartość, która ma być predykowana przez klasyfikator) a jaką w odniesieniu do brakujących cech (wartość/wartości, które są wejściem klasyfikatora)?
- Oceń skuteczność klasyfikacji i porównaj ją z pozostałymi podejściami
Konwersja danych
Daty i czasy
Konwersja dat i czasów
Dane bardzo często związane są z datą/czasem wystąpienia, rejestracji itp. Przykładowo, używany zbiór danych w kolumnie Date przechowuje datę sprzedaży. Ponieważ zawiera ona znaki inne niż cyfry/punkt dziesiętny zaczytywana jest domyślnie z pliku CSV jako string:
print(type(df.loc[0, "Date"]))W celu dalszego wygodnego wykorzystania takie dane wymagają konwersji na format zrozumiały dla wykorzystywanych narzędzi. W Pandas mamy do dyspozycji funkcję to_datetime() pozwalającą na utworzenie serii/indeksu typu Datetime na podstawie źródłowych liczb, napisów etc:
df.loc[:, "Datetime"] = pd.to_datetime(df.loc[:, "Date"])Mnogość formatów zapisu dat i czasów (np. DD-MM-YYYY lub MM-DD-YYYY) powoduje jednak, że funkcja to_datetime może niepoprawnie odgadnąć format wejściowy. Porównaj uzyskane kolumny Date i Datetime - czy dane wejściowe były zawsze interpretowane tak samo?
Funkcja to_datetime ma wiele dodatkowych opcji: to_datetime. Spróbuj za pommocą parametru format= wymusić poprawny format źródłowy daty.
Wyznaczanie zakresów dat i interwałów
Serię dat z określonym początkiem, końcem i okresem można wygenerować funkcją date_range: dokumentacja
Zakres (interwał) dat, który może służyć do wyłuskania fragmentu tabeli można wygenerować funkcją Interval, podając jako granice Timestamp:
Przykładowo:
year_2017 = pd.Interval(pd.Timestamp('2017-01-01 00:00:00'), pd.Timestamp('2018-01-01 00:00:00'), closed='left')Wyznaczanie dnia tygodnia
Pewne cechy wykazują zmienność nie wprost od upływu czasu (monotonicznie), co np. od dnia tygodnia, dnia miesiąca itp. Dysponując datą/czasem w formacie datetime łatwo skonwertujemy ją na dzień tygodnia w formacie liczbowym od 0 (poniedziałek) do 6 (niedziela) przy pomocy pola DataFrame.dt.dayofweek.
df.loc[:, "Day of week"] = df.loc[:, "Datetime"].dt.dayofweek🔥 Zadanie 🔥
Wykreśl histogram liczby dokonanych transakcji w zależności od dnia tygodnia.
Zmienne nominalne
Zmienne nominalne (categorical data) to takie, które przyjmują wartości z określonego, skończonego zbioru, dla których nie istnieje żadne domyślne uporządkowanie (np. miasto urodzenia, płeć). W przypadku programowania można posłużyć się analogią do typów wyliczeniowych (np. enum z C++). Zazwyczaj kategorii będzie znacznie mniej niż próbek danych.
Konwersja na zmienną nominalną
Dane typu categorical możemy wygenerować na kilka sposobów, np ręcznie, wymuszając typ danych category parametrem dtype:
categorical_series = pd.Series(["a", "b", "c", "a"], dtype="category")
print(categorical_series)lub konwertując istniejącą kolumnę DataFrame:
df["B"] = df["A"].astype("category")Dla omawianej bazy sprzedaży nieruchomości możemy przykładowo skonwertować kolumnę RegionName:
df.loc[:, "RegionName"] = df.loc[:, "RegionName"].astype("category")
print(df["Regionname"])Łączenie zmiennych nominalnych (usuwanie literówek) przy pomocy fuzzywuzzy
W przypadku ręcznego wprowadzania danych np. przez osoby ankietowane lub przez różne instytucje, dane nominalne różnią się wielkością liter, sposobem zapisu (ze znakami diakrytycznymi lub bez) lub zawierają literówki. W przypadku nazw miejsc nazwy mogą posiadać lub nie dodatkowe człony (np. Ostrów i Ostrów Wlkp i Ostrow Wielkoposlki, jak również ostrow wlkp). Wszystkie takie wpisy powinny trafić do jednej kategorii.
W przypadku zmiany różnicy w wielkości liter możliwe jest konwersja wszystkich elementów w kolumnie na np. małe litery oraz usunięcie znaków spacji. Sprawdź (używając np.unique(...)) ile różnych unikalnych elementów w kolumnie Suburb? Porównaj ten wynik z wynikiem otrzymanym po znormalizowaniu wielkości liter oraz usunięciu końcowych znaków spacji
# zmiana na małe litery
df['Suburb'] = df['Suburb'].str.lower()
# usunięcie końcowych spacji
df['Suburb'] = df['Suburb'].str.strip()W danych mogą się jednak znajdować takie same elementy różniące się literą (literówka) lub posiadające dodatkowe człony w nazwie. Do porównania dwóch napisów, lub napisu z listą innych napisów można użyć moduł fuzzywuzzy
import fuzzywuzzy.process
fuzzywuzzy.process.extract('Ostrów',['ostrow', 'Ostrów Wlkp', 'ostrów wlkp', 'Ostrzeszów'])Funkcja zwróci listę krotek, gdzie drugi element określa podobieństwo. Do scalenia pewnego ciągu znaków z elementami kolumny pandas, może służyć funkcja:
import fuzzywuzzy.process
def replace_matches_in_column(df, column, string_to_match, min_ratio = 90):
# get a list of unique strings
strings = df[column].unique()
# get the top 10 closest matches to our input string
matches = fuzzywuzzy.process.extract(string_to_match, strings,
limit=10, scorer=fuzzywuzzy.fuzz.token_sort_ratio)
# only get matches with a ratio > 90
close_matches = [matches[0] for matches in matches if matches[1] >= min_ratio]
# get the rows of all the close matches in our dataframe
rows_with_matches = df[column].isin(close_matches)
# replace all rows with close matches with the input matches
df.loc[rows_with_matches, column] = string_to_match🔥 Zadanie 🔥
Podmień wczytywany plik na melb_data_distorted.csv, w którym w niektórych kolumnach tekstowych zostały wprowadzone typowe pomyłki lub różnice w zapisie.
Spróbuj zastosować funkcję replace_matches_in_column do scalenia elementów w kolumnie Suburb, pamiętaj, że trzeba ją wywołać osobno dla każdego unikalnego elementu string_to_match. Ile unikalnych elementów zostanie, jeśli minimalny próg podobieństwa ustalisz na wartość 90?
Konwersja zmienna porządkowa → wartości liczbowe
Wykorzystanie zmiennych jako wejścia w systemach klasyfikacji/regresji wymaga podania wartości liczbowej. Jednym z podejść, które można zastosować jest przypisanie poszczególnym wartościom zmiennej nominalnej specyficznej wartości (np. 1, 2, 3, ...)
from sklearn.preprocessing import LabelEncoder
# Make copy to avoid changing original data
label_train = train_df.copy()
label_test = test_df.copy()
# Apply label encoder to each column with categorical data
label_encoder = LabelEncoder()
col='CouncilArea'
label_train[col] = label_encoder.fit_transform(label_train[col])
label_test[col] = label_encoder.transform(label_test[col])- ❓Zastanów się czy podejście to sprawdzi się w celu uwzględnienia w predyktorze ceny nazw obszarów administracyjnych, lub dni tygodnia w których nastąpiła sprzedaż?
- ❓Zastanów się czy podejście takie sprawdzi się do klasyfikacji zmiennej nominalnej siła wiatru, gdzie zbiorem wartości jest [brak, słaby, silny, bardzo silny]?
Zmienna nominalna → enkoder binarny
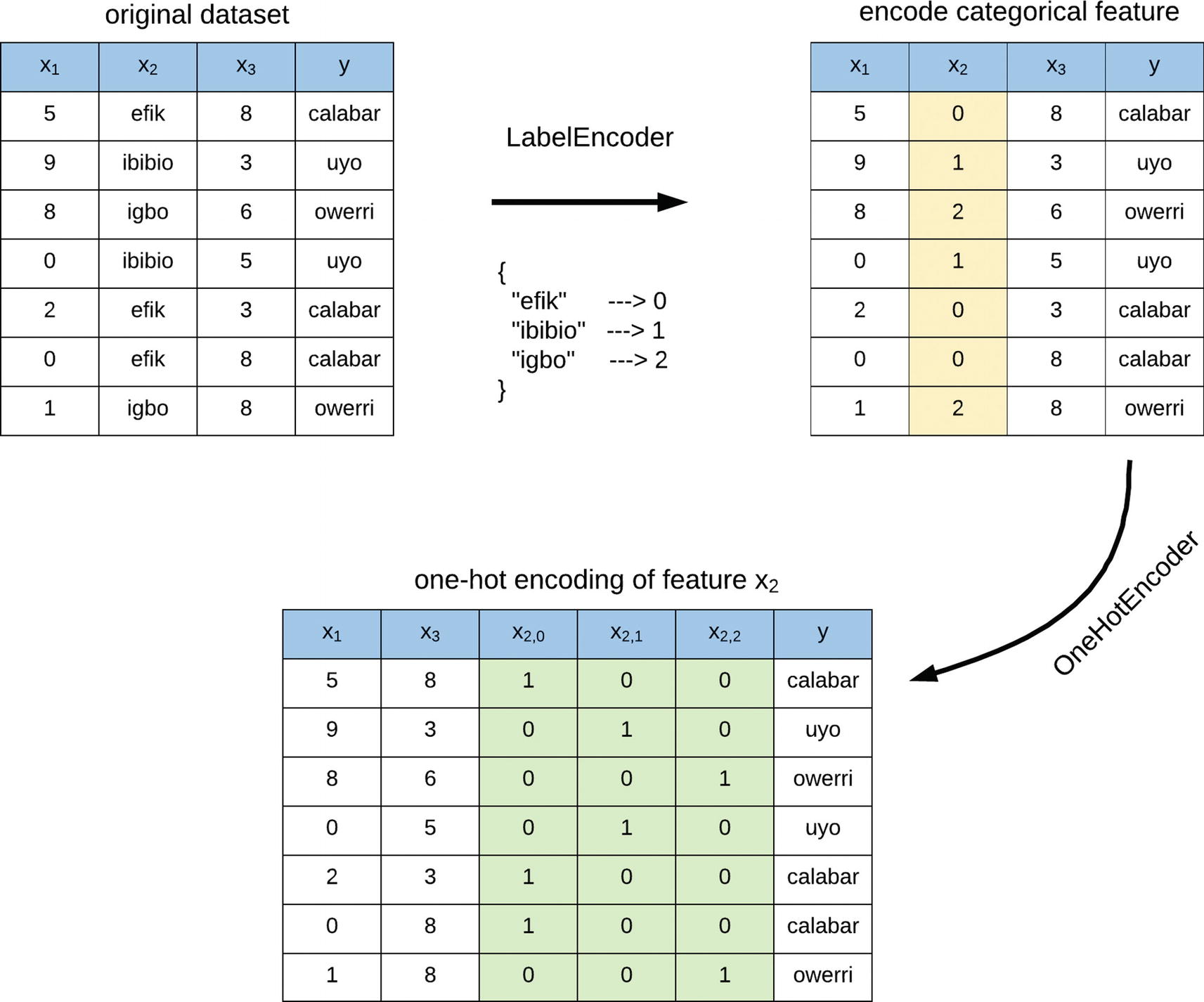
Innym możliwym podejściem jest konwersja zmiennej nominalnej o n wartościach na n kolumn, z których każda określa wartością 0 lub 1 to czy dana wartość wystąpiła. Procedura ta nazwya się również one-hot encoder. Porównanie sposobu transformacji za pomocą LabelEncodera i LabelBinarizer/(połączenia LabelEncoder i OneHotEncoder) przedstawiono na rysunku:
{kind=link}
from sklearn.preprocessing import LabelBinarizer
# Make copy to avoid changing original data
label_train = train_df.copy()
label_test = test_df.copy()
label_binarizer = LabelBinarizer()
col = 'CouncilArea'
lb_results = label_binarizer.fit_transform(label_train[col])
lb_results_df = pd.DataFrame(lb_results, columns=label_binarizer.classes_)- ❓Zastanów się czy podejście to sprawdzi się w celu uwzględnienia w predyktorze ceny nazw obszarów administracyjnych, lub dni tygodnia w których nastąpiła sprzedaż?
- ❓Zastanów się czy podejście takie sprawdzi się do klasyfikacji zmiennej nominalnej siła wiatru, gdzie zbiorem wartości jest [brak, słaby, silny, bardzo silny]?
Autorzy: Piotr Kaczmarek i Jakub Tomczyński