Lab 07 - Analiza wstępna i przetwarzanie danych
Lab 06 - Analiza i wstępne przetwarzanie danych
Wprowadzenie
Przedmiotowe zajęcia wykorzystują zbiór danych, lub alternatywny link. Zbiór zawiera informację o cenach sprzedaży nieruchomości oraz ich cechy. Zapoznaj się z opisem poszczególnych kolumn. W EAD chodzi o zrozumienie zależności między cechami w tym dla przedmiotowego datasetu zależności między cechami a ceną sprzedaży.
Macierz korelacja a metryki podobieństwa
Macierz korealacji jest dość popularnym sposobem analizy zależności między poszczególnymi parami cech. Najbardziej powszechni stosowana korelacja Pearsona (df.corr()) umożliwia wykrycie relacji z silnym komponentem liniowym, w przypadku niektórych typów nieliniowości można stosować metody bazujące na korelacji rozkładu (korelacje Spearmana (df.corr('spearman')))
Wykrycie bardziej złożonych zależności może nie być możliwe. W praktyce stosowane są również inne metody umożliwiające ocenę zależności między poszczególnymi cechami: 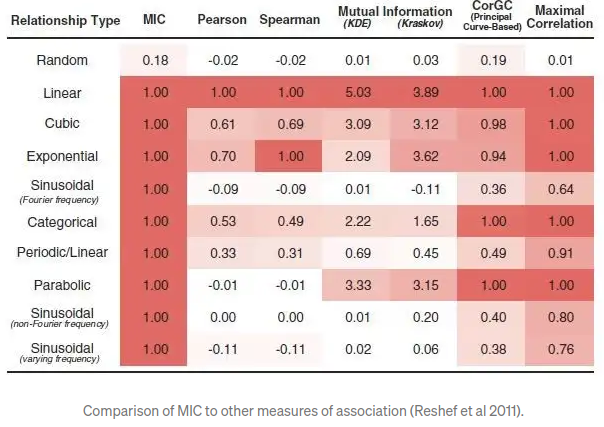
- MIC (maximal information coefficient) pozwala na mapowanie zależności o charakterze wielomianowym lub harmonicznym. Macierz podobieństwa jest symetryczna.
- PPS (predictive power score). Podobieństwo jest określona na podstawie znormalizowanej metryki określającej dokładność modelu opartego o regresor drzewiasty testowanego z wykorzystaniem k-krotnej walidacji. Konsekwencją jest otrzymanie niesymetrycznej macierzy podobieństwa (dana cech A (np. nazwa miasta) może być estymowana na podstawie cechy B (kod pocztowy), jednak odwrócenie tego procesu jest niemożliwe) PPS w implementacji pythona stosuje encoder stąd analiza dotyczy również cech nominalnych. W dalszej części zajęć próbujesz zastosować tą metodą w celu porównania z macierzą korelacji.
import ppscore as pps
pps_mat = pps.matrix(df_train)
pps_mat = pps_mat[['x', 'y', 'ppscore']].pivot(columns='x', index='y', values='ppscore')Przebieg ćwiczenia
Podczas laboratorium spróbuj uruchomić i przyswoić sobie metodykę analizy części cech zaprezentowaną w notatniku. Klikając przycisk Copy and Edit możesz uruchamiać poszczególne sekcje i modyfikować ich działanie. Spróbuj zrozumieć logikę procesu eksploracji który obejmuje:
- Analizę poszczególnych zmiennych, usuwanie outlierów
- Analizę zależności między zmiennymi w formie wykresu punktowego, analizy współczynnika korelacji
- Analizę rozkładów poszczególnych zmiennych, oraz porównanie go z standardowymi rozkładami (np. normalnym) lub rozkładami innych zmiennych.
- W końcowym etapie analiza może zakończyć się wnioskami dotyczącymi istotności poszczególnych zmiennych oraz relacji między nimi.
Dalsze działania
Po przeanalizowaniu zawartości notatnika spróbuj wprowadzić następujące zmiany:
- Zmodyfikuj procedurę usuwającą outliery. W tym celu dla sekcji
Out liars->Univariant analysiswyświetl zawartość kolumnySalesPricejako box plot. - Dokonaj usunięcia outlierów traktując jako outliery elementy znajdujące się poza zakresem
<Q1 - 1.5*IRQ, Q3 + 1.5*IRQ>, gdzieIRQ=Q3-Q1. Do wyznaczenia wartości kwartyli wykorzystaj metodęDataFrame.quantile(q=q), gdzieqjest wartością kwantyla (dlaQ1wynosi 0.25, dlaQ30.75) - Popraw procedurę usuwania odstających wartości w sekcji
Bivariate analysistak żeby indeksy wartości odstających były określane przez podanie zakresu odczytanego z wykresu. Spróbuj znaleźć zmienne dla których pojawia się podobne zjawisko - Przeanalizuj kolumnę
2ndFlrSFokreśl z jakimi innymi cechami jest silnie (korelacja >0.6) skorelowana. - Zastanów się i spróbuj uzasadnić czy warto do klasyfikacji wykorzystać równocześnie cechy
1stFlrSFiTotalBsmtSF - Zamiast macierzy korelacji wykorzystaj metodę analizy opartą o Predictive Power Score
- Wybierając cechy numeryczne i nominalne spróbuj ocenić dokładność klasyfikacji przy pomocy lasu drzew. Wybierz 2 zestawy cech bazując na macierzy korelacji i metodzie PPS. Zastanów się czy w wynikach metody PPS, jeśli celem jest predykcja ceny to czy brać pod uwagę wyniki w wierszu czy kolumnie?. Pamiętaj żeby wykorzystać zbiór uczący i testowy, a parametry preprocessingu wyznaczone dla zbioru uczącego zastosować dla zbioru testowego (bez ich ponownego liczenia)
Autor: Piotr Kaczmarek