Lab 03 - Filtry, strumienie oraz przetwarzanie potokowe
Filtry, strumienie oraz przetwarzanie potokowe
Standardowe wejście/wyjście
Każdy proces domyślnie korzysta ze standardowych strumieni danych, będących abstrakcją źródła lub ujścia danych. Dla każdego procesu system tworzy standardowy strumień wejściowy (ang. standard input), reprezentujący urządzenia wejściowe, np. klawiaturę i dysk, standardowy strumień wyjściowy (ang. standard output), którym może być terminal (monitor komputera) lub plik oraz standardowy strumień diagnostyczny (ang. standard error). Strumienie wejściowy, wyjściowy i diagnostyczny oznaczane są odpowiednio: stdin, stdout, stderr. Każdy strumień ma odpowiadające mu wartości: stdin - 0, stdout - 1 i stderr - 2.
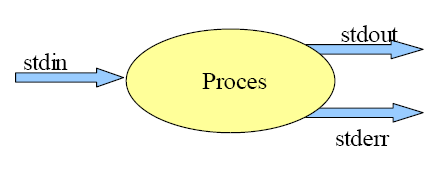
Standardowe strumienie procesów charakteryzują się następującymi cechami:
- Dane odczytywane są poprzez standardowe wejście.
- Dane wypisywane są na standardowym wyjściu lub standardowym wyjściu diagnostycznym.
- Raz przeczytanych danych nie można ponownie przeczytać.
Działanie standardowych strumieni ilustruje program cat. Uruchomienie tego programu bez argumentów powoduje przepisanie tego, co zostanie wpisane z wejścia standardowego (klawiatury) na wyjście standardowe (okno terminala). Wpisywanie danych z klawiatury można zakończyć za pomocą kombinacji Ctrl-D (reprezentowane w listingach jako ^D).
Przekierowanie wejścia/wyjścia procesów
Istnieje możliwość przeadresowania strumieni wyjściowych i wejściowych. Zmianę standardowego wejścia, wyjścia i wyjścia diagnostycznego można dokonać za pomocą operatorów: >, <, >>, <<.
Operator > powoduje przeadresowanie standardowego wyjścia, czyli utworzenie pliku i zapisanie w nim tego, co proces wypisałby na standardowym wyjściu. Jeśli wskazany plik już istnieje, zostanie on usunięty i utworzony na nowo.
cat > plik.txt
To jest plik.
Ala ma kota.
^DOperator < powoduje przeadresowanie standardowego wejścia procesu, czyli pobranie danych wejściowych ze wskazanego pliku:
cat < plik.txt
To jest plik.
Ala ma kota.Operatory > i < można używać jednocześnie, przeadresowując zarówno wyjście jak i wejście, co spowoduje, że zawartość pliku plik.txt zostaje skopiowana do pliku plik_nowy.txt:
cat < plik.txt > plik_nowy.txtOperator >> przeadresowuje standardowe wyjście, dopisując wyniki działania programu na końcu istniejącego pliku:
cat >> plik.txt
Kot ma Ale.
^DOperator << powoduje, że do procesu zostaną przekazane dane ze standardowego wejścia aż do napotkania wskazanego napisu:
cat << przerwa
> Ala ma kota
> Kot ma Ale
> przerwa
Ala ma kota
Kot ma Ale.Niektóre polecenia równolegle z wyświetlanymi na standardowym wyjściu informacjami wysyłają dodatkowe informacje informujące o błędach przetwarzania na standardowe wyjście diagnostyczne. Istnieje możliwość niezależnego przekierowania strumienia diagnostycznego, poprzez operator > poprzedzony numerem wyjścia diagnostycznego, czyli 2:
cat plik1.txt plik2.txt 2> plik3.errPolecenie to spowoduje wyświetlenie zawartości plików plik1.txt i plik2.txt oraz zapisanie informacji o błędach do pliku plik3.err.
W celu pominięcia komunikatów o błędach, wyjście diagnostyczne można przeadresować do pliku /dev/null. Wszystko co zostaje wysłane do pliku null, znajdującego się w katalogu /dev zostanie utracone:
cat plik1.txt plik2.txt> plik3.txt 2> /dev/nullPolecenie to spowoduje zapisanie kolejno zawartości plików plik1.txt i plik2.txt do pliku plik3.txt oraz jednocześnie zignoruje komunikaty o błędach.
W przypadku gdy strumień diagnostyczny ma trafiać tam, gdzie strumień wyjściowy, należy użyć zapisu 2>&1:
cat plik1.txt plik2.txt> plik3.txt 2>&1Wiele programów konsolowych działających na strumieniach może przyjąć również nazwę pliku jako wejście: polecenie cat < plik.txt wygeneruje taki sam efekt jak cat plik.txt, a w przypadku skomplikowanego potoku wersja druga może okazać się znacząco czytelniejsza. Dodatkowo, wiele programów akceptuje przekazanie - jako nazwy pliku, co w zależności od kontekstu oznacza wejście lub wyjście standardowe.
Przetwarzanie potokowe
Standardowe wyjście jednego procesu może być połączone ze standardowym wejściem innego procesu, tworząc tzw. potok pomiędzy tymi procesami.

Przetwarzanie potokowe polega na buforowaniu przez system danych produkowanych przez pierwszy proces i następnie odczytywaniu tych danych przez drugi proces. Innymi słowy proces w potoku czyta dane z wejścia, które zostało przeadresowane na wyjście procesu poprzedniego. W potoku może brać udział jednocześnie kilka procesów. Do przekierowania danych do kolejnego procesu używany jest znak |. Poniżej podano przykłady potoków:
Proces ls podaje wynik procesowi more, który w efekcie wyświetla listing strona po stronie:
ls -al | moreProces who podaje wynik procesowi sort, podając posortowaną listę pracowników pracujących w systemie:
who | sortProces ps podaje wynik procesowi grep, wyszukując na liście procesów linii zawierających słowo csh:
ps -ef | grep cshProces ls podaje wynik procesowi sort, który następnie podaje wynik procesowi head, wyświetlając pierwszych 10 największych plików:
ls -l /usr/bin | sort -bnr +4 -5 | headFiltry
Istnieją programy, których zadaniem jest odczyt danych ze standardowego wejścia, przetworzenie tych danych i ich zapis na standardowe wyjście. Programy takie nazywane są filtrami i są szeroko wykorzystywane w przetwarzaniu potokowym. Poniżej przedstawiono najczęściej wykorzystywane filtry:
cat- najprostszy filtr, nie wprowadzający zmian do przetwarzanych danych. Użyteczne przełączniki:-sz paru pustych linii robi jedną-nnumeruje wszystkie linie-bnumeruje niepuste linie-Apokazuje znaki specjalne
head- wyświetla początkową część pliku o podanej nazwie lub danych wejściowych otrzymanych z potoku gdy nazwa pliku nie jest podana. Standardowo wyświetlanych jest pierwszych 10 linii odczytanych danych. Używając przełączników liczbę tą można zmienić:-cpozwala określić liczbę wyświetlanych znaków-npozwala określić liczbę wyświetlanych linii
tail- wyświetla końcową część pliku o podanej nazwie lub danych wejściowych otrzymanych z potoku, gdy nazwa pliku nie jest podana,. Standardowo wyświetlanych jest ostatnich 10 linii danych. Używając przełączników liczbę tą można zmienić:-cpozwala określić liczbę wyświetlanych znaków-npozwala określić liczbę wyświetlanych linii-fpowoduje, że dane po zapisaniu ich do pliku są wyświetlane na standardowym wyjściu
sort- służy do sortowania danych wejściowych, które to domyślnie sortowane są leksykograficznie. Sortowanie danych odbywa się liniami. Najważniejsze przełączniki:-npozwala sortować numerycznie-bignoruje przy sortowaniu spacje znajdujące się na początku linii-tpozwala zmienić domyślny separator kolumn, którym są znaki tabulacji lub spacji-fpozwala ignorować przy sortowaniu wielkość liter-rodwraca kolejność sortowania+liczbapozwala by sortowanie odbywało się względem dowolnej kolumny (a nie początku linii). Liczba określa liczbę kolumn pominiętych przy sortowaniu-o nazwa_plikuzapisuje rezultat sortowania do pliku o podanej nazwie
uniq- umożliwia usunięcie powtarzających się, sąsiadujących linii danych wejściowych.-dwyświetla z danych wejściowych tylko linie powtarzające się-uwyświetla z danych wejściowych tylko linie unikalne-czlicza liczbę powtórzeń
wc- zlicza znaki, słowa i linie w podanych danych wejściowych. Standardowo wyświetlane są wszystkie trzy wartości, ale można to zmienić:-lpozwala zliczać tylko linie-wpozwala zliczać tylko słowa-cpozwala zliczać tylko znaki
tr- pozwala zamienić łańcuchy tekstowe, które podawane są jako argumenty wejściowe. Znaki z pierwszego łańcuch zamieniane są na znaki z drugiego łańcucha. Dodatkowo, dzięki przełącznikom możliwe jest następujące przetwarzanie:-dusuwa podane po przełączniku znaki-susuwa powtarzające się sąsiednie znaki
cut- pozwala wyświetlić fragmenty wierszy danych wejściowych. Zwykle jest to wycinanie odpowiednich kolumn-cpozwala określić pozycję znakowe wycinanych fragmentów wierszy, np.-c 1-72wyświetla pierwsze 72 znaki każdego wiersza-fpozwala określić numery wycinanych kolumn, np.-f1,3-5,10wyświetla pierwszą kolumnę, kolumny od 3 do 5 oraz kolumnę 10.-dpozwala zmienić domyślny separator kolumn, którym jest znak tabulacji
grep [opcje] wyrażenie [lista_plików]- przeszukuje dane pochodzące ze standardowego wejścia lub pliki wyszczególnione na liście plików, wypisując tylko linie zawierające szukane wyrażenie. Szukane wyrażenie zapisywane jest za pomocą wyrażenia regularnego. Najważniejsze przełączniki:-vwyszukuje linie nie zawierające szukanego wzorca-cpodaje liczbę odszukanych wyrażeń-iignoruje wielkość liter przy wyszukiwaniu-nwyświetla numery linii zawierających dany wzorzec-hprzy wyświetlaniu linii zawierających szukany wzorzec pomija nazwy plików-rpozwala na przeszukiwanie rekurencyjne, np.grep wzorzec -r katalog-lpokazuje nazwy plików zawierających określony wzorzec-Lpokazuje nazwy plików nie zawierających określonego wzorca
Zasady konstrukcji podstawowych wyrażeń regularnych opisujących szukany wzorzec są następujące:
.- reprezentuje dowolny znak[abc]- oznacza jeden ze znaków a, b lub c[a-z]- oznacza jeden ze znaków z podanego zakresu[^0-9]- oznacza dopełnienie podanego zbioru (znaki inne niż od0do9)*- reprezentuje powtórzenie dowolną liczbę razy (0 lub więcej) wyrażenia znajdującego się bezpośrednio po lewej stronie np:.*oznacza dowolny ciąg znakówA[a]*określa A, Aa, Aaa, Aaaaaaaaa, itd.
^- reprezentuje początek linii$- reprezentuje koniec linii
Domyślnie grep pracuje w uproszczonym trybie, gdzie znaki ?, +, {, }, |, ( oraz ) traktowane są dosłownie. Aby uzyskać zgodność z wyrażeniami regularnymi stosowanymi w innych językach (extended regular expressions), należy stosować grep z przełącznikiem -E lub używać polecenia egrep (które wewnętrznie wywołuje grep z przełącznikiem -E). Rozbudowuje to dostępne znaczniki między innymi o:
+- jedno lub więcej wystąpień poprzedzającego znaku{n}- n-krotne wystąpienie poprzedzającego znaku{n,}- oznacza co najmniej n-krotne wystąpienie znaku występującego bezpośrednio po lewej stronie nawiasów{,m}- oznacza co najwyżej m-krotne wystąpienie znaku występującego po lewej stronie nawiasów{n,m}- oznacza co najmniej n-krotne i co najwyżej m-krotne wystąpienie znaku występującego po lewej stronie nawiasów
Jeśli chcemy, aby znak mający znaczenie specjalne w wyrażeniach regularnych (np. ., *, {, }, (, ), ^, [, ], \, <, >, $) został potraktowany dosłownie, musimy poprzedzić go backslashem (\). Ponadto, ponieważ wiele z wymienionych znaków ma w powłoce bash znaczenie specjalne, całe wyrażenie wpisane w konsoli należy umieścić w pojedynczym cudzysłowie ('), aby uniknąć ich interpretacji przez powłokę.
Przykłady potoków z wyrażeniami regularnymi:
Proste wyrażenie regularne - przeszukuje plik /etc/group pod kątem słowa student:
grep student /etc/groupZaawansowane wyrażenia:
Wyświetla elementy znajdujące się w głównym katalogu, o nazwach zaczynających się na s i minimum trzech następujących dowolnych znakach:
ls / | egrep '^s.{3,}'Listuje zawartość pliku /etc/hosts, sortuje ją, a następnie przeszukuje pod kątem wystąpienia adresu IP - liczby w formacie w.x.y.z, gdzie w, x, y oraz z to liczby o od 1 do 3 cyfr. Zwróć uwagę na backslash przed kropkami powodujący, że kropka jest traktowana dosłownie, a nie jako dowolny znak:
cat /etc/hosts | sort | egrep '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}'Nowa linia na końcu pliku
Zwyczajowo w systemach uniksowych pliki tekstowe (konfiguracyjne, źródłowe, skrypty itp.) zakończone są znakiem nowej linii. Niektóre edytory (np. nano) same dodają znak nowej linii przy każdej edycji pliku.
Niektóre z przedstawionych poleceń mogą wymagać obecności znaku końca linii w ostatnim wierszu. W przypadku problemów z wczytywaniem ostatniego wiersza możesz to zweryfikować wyświetlając plik np. cat:
student@vbox-xubuntu-rtos:~$ cat zly_plik
To jest linia tekstu
To jest kolejna liniastudent@vbox-xubuntu-rtos:~$ cat dobry_plik
A tu jest zawartosc innego pliku
Zakonczonego znakiem nowej linii
student@vbox-xubuntu-rtos:~$ Zwróć uwagę, że po wyświetleniu pliku nie zakończonego znakiem nowej linii znak zachęty (student@vbox...) wyświetla się w tym samym wierszu, co zawartość pliku.
Zadania do samodzielnego wykonania
- Wyświetl plik /etc/passwd z podziałem na strony przyjmując, że strona ma 5 linii tekstu. Podpowiedź: sprawdź program
more - Stwórz pliki tekst1 oraz tekst2, wypełnij kilkoma linijkami tekstu. Korzystając z polecenia
catutwórz plik tekst3, który będzie składał się z zawartości plików tekst1 oraz tekst2. - Wyświetl po 5 pierwszych linii wszystkich plików w swoim katalogu domowym w taki sposób, aby nie były wyświetlane ich nazwy. Podpowiedź: pamiętaj, że z programami, które przyjmują jako argumenty nazwy plików możesz używać wzorców.
- Wyświetl linie o numerach 3, 4 i 5 z pliku /etc/passwd
- Wyświetl linie o numerach 7, 6 i 5 licząc od końca pliku /etc/passwd (czyli kolejno 7. od końca, 6. od końca i 5. od końca)
- Wyświetl zawartość /etc/passwd w jednej linii
- Za pomocą filtru
trwykonaj modyfikację pliku, polegającą na umieszczeniu każdego słowa (oddzielonych spacją) w osobnej linii. Podpowiedź: aby przekazać znak spacji jako argument, musisz umieścić go w cudzysłowie - Zlicz wszystkie pliki znajdujące się w katalogu /etc i jego podkatalogach
- Napisz polecenie zliczające sumę znaków z pierwszych trzech linii pliku /etc/passwd
- Wyświetl listę plików z aktualnego katalogu, zamieniając wszystkie małe litery na duże.
- Wyświetl listę praw dostępu do plików w aktualnym katalogu, ich rozmiar i nazwę
- Wyświetl listę plików w aktualnym katalogu, posortowaną według rozmiaru pliku
- Wyświetl zawartość pliku /etc/passwd posortowaną wg numerów UID w kolejności od największego do najmniejszego
- Wyświetl zawartość pliku /etc/passwd posortowaną najpierw wg numerów GID w kolejności od największego do najmniejszego, a następnie UID
- Podaj nazwy trzech najmniejszych plików w katalogu posortowane wg nazwy
- W pliku
/etc/servicesprzechowywana jest lista popularnych usług sieciowych, wraz z numerami portów i protokołem. Wylistuj (tylko) nazwy usług, które korzystają z protokołuUDP. - Wyświetl, ile wirtualnych terminali (
dev/tty) o numerach z zakresu 50-69 znajduje się w systemie. - Zbuduj potok, który wyświetli w terminalu PID procesu cupsd.
Autorzy: Adam Bondyra, Jakub Tomczyński
Opracowano na podstawie materiałów projektu Otwartych Studiów Informatycznych (http://wazniak.mimuw.edu.pl/).