02 - Profilowanie algorytmów - metody
Systemy Wbudowane i Przetwarzanie Brzegowe
Politechnika Poznańska, Instytut Robotyki i Inteligencji Maszynowej
![]()
Ćwiczenie laboratoryjne 2: Profilowanie algorytmów - metody
Powrót do spisu treści ćwiczeń laboratoryjnych
Wstęp
Algorytmy uczenia maszynowego, jak również metody opartę o uczenie głębokie są coraz częściej wykorzystywane w systemach wbudowanych. Jednakże wiele z nich wymaga obliczeń, które są zbyt złożone dla urządzeń brzegowych, a tym bardziej dla mikrokontrolerów. W tym ćwiczeniu zapoznamy się ze złożonością obliczeniową algorytmów uczenia maszynowego oraz z metodami wyznaczania parametrów modeli opartych o sieci neuronowe.
Profilowanie kodu źródłowego
1. timeit
Moduł timeit jest prostym rozwiązaniem do pomiaru czasu wykonywania fragmentu kodu. Biblioteka ta jest dostępna w standardowej wersji języka Pythona i nie wymaga instalacji dodatkowych pakietów. Można wyróżnić dwie metody dostępne w module timeit:
timeit- wykonuje podany kod raz i zwraca czas wykonaniarepeat- wykonuje podany kod kilka razy i zwraca listę czasów wykonania
import time
import timeit
import numpy as np
# 1. the simplest usage
print(timeit.timeit('[(a, b) for a in (1,3,5) for b in (2,4,6)]', number=1))
print(np.mean(timeit.repeat('[(a, b) for a in (1,3,5) for b in (2,4,6)]', repeat=5, number=1)))
def test_func_1():
s = 0.0
for i in range(1000):
s += round(pow(i, 1/2), 2)
time.sleep(0.01)
# 2. test of a non-parametrized function
print(np.mean(timeit.repeat(test_func_1, repeat=5, number=1)))
def test_func_2(n):
s = 0.0
for i in range(n):
s += round(pow(i, 1/2), 2)
time.sleep(0.01)
setup = '''
from __main__ import test_func_2
n = 1000
'''
# 3. test of a parametrized function
print(np.mean(timeit.repeat('test_func_2(n)', setup=setup, repeat=5, number=1)))2. line_profiler
line_profiler jest modułem profilowania funkcji linia po linii. Do tego celu wykorzystuje dekorator @profile, a rezultaty zapisuje w skryptach kernprof. W celu uruchomienia profilowania należy wykonać następujące kroki:
- Wklej poniższy kod źródłowy do pliku
line_profiler_test.py.
import time
@profile
def sleep_function():
print('Sleep function start')
time.sleep(5)
print('Sleep function end')
if __name__ == '__main__':
sleep_function()- Uruchom poniższe komendy w konsoli. W pierwszej linii wykonywany jest profilowanie, a w drugiej wyświetlany jest wynik.
kernprof -l line_profiler_test.py
python -m line_profiler line_profiler_test.py.lprof
Uwaga: Jeśli po wywołaniu modułu line_profiler wystąpi błąd: No module named line_profiler zainstaluj pakiet korzystając z systemu zarządzania pakietami dla środowiska języka Python: pip install line-profiler.
- Otrzymany wynik powinien wyglądać następująco:
Total time: 5.00152 s
File: line_profiler_test.py
Function: sleep_function at line 4
Line # Hits Time Per Hit % Time Line Contents
==============================================================
4 @profile
5 def sleep_function():
6 1 17.0 17.0 0.0 print('Sleep function start')
7 1 5001463.2 5001463.2 100.0 time.sleep(5)
8 1 38.4 38.4 0.0 print('Sleep function end')
3. memory_profiler
memory_profiler jest modułem profilowania zużycia pamięci przez procesy, jak również przez poszczególne funkcje. Do tego celu wykorzystuje dekorator @profile. W celu uruchomienia profilowania należy wykonać następujące kroki:
- Wklej poniższy kod źródłowy do pliku
memory_profiler_test.py.
@profile
def data_append_function():
print('Data append function start')
data = []
for i in range(100000):
data_in = i // 2
data.append(data_in)
print('Data append function end')
return data
if __name__ == '__main__':
_ = data_append_function()- Uruchom poniższą komendę w konsoli.
python -m memory_profiler memory_profiler_test.py
Uwaga: Jeśli po wywołaniu modułu memory_profiler wystąpi błąd: No module named memory_profiler zainstaluj pakiet korzystając z systemu zarządzania pakietami dla środowiska języka Python: pip install memory-profiler.
- Otrzymany wynik powinien wyglądać następująco:
Filename: memory_profiler_test.py
Line # Mem usage Increment Occurrences Line Contents
=============================================================
11 41.387 MiB 41.387 MiB 1 @profile
12 def data_append_function():
13 41.387 MiB 0.000 MiB 1 print('Data append function start')
14 41.387 MiB 0.000 MiB 1 data = []
15 44.996 MiB 0.000 MiB 100001 for i in range(100000):
16 44.996 MiB 0.000 MiB 100000 data_in = i // 2
17 44.996 MiB 3.609 MiB 100000 data.append(data_in)
18
19 44.996 MiB 0.000 MiB 1 print('Data append function end')
20 44.996 MiB 0.000 MiB 1 return data
Zadanie 1. Korzystając z narzędzi do profilowania zbadaj wydajność, czas wykonywania oraz zużycie pamięci poniższego kodu źródłowego. Przeanalizuj, w których miejscach występuje największe zużycie pamięci oraz które fragmenty kodu są najbardziej kosztowne pod względem czasu wykonywania.
Kod źródłowy
from typing import List
import numpy as np
import pandas as pd
def get_data() -> pd.DataFrame:
url = "https://zenodo.org/record/2826939/files/Folsom_irradiance.csv?download=1"
return pd.read_csv(url)
def create_new_timestamp(df: pd.DataFrame) -> List[str]:
"""
Funkcja zmieniająca format znacznika czasu z YYYY-MM-DD hh:mm:ss na YYYYmmdd_HHMMSS
np. 2014-01-02 08:00:00 -> 20140102_080000
"""
new_time_stamps = []
for idx in range(len(df)):
timestamp = df.iloc[idx]['timeStamp']
year = timestamp[:4]
month = timestamp[5:7]
day = timestamp[8:10]
hour = timestamp[11:13]
minute = timestamp[14:16]
second = timestamp[17:19]
new_time_stamp = year + month + day + '_' + hour + minute + second
new_time_stamps.append(new_time_stamp)
return new_time_stamps
def get_max_ghi_date(df):
"""
Funkcja znajdująca największą wartość GHI (Global Horizontal Irradiance)
oraz czas, w którym ta wartość została zarejestrowana
"""
max_val = df['ghi'].values.max()
idx = df['ghi'].values.tolist().index(max_val)
ghi = df["ghi"].values[idx]
date = df["new_timestamp"].values[idx]
print(f'Max GHI was equal {ghi} on {date} UTC')
def main():
df = get_data()
df['new_timestamp'] = create_new_timestamp(df)
get_max_ghi_date(df)
if __name__ == '__main__':
main()Metody optymalizacji kodu źródłowego
1. Wykorzystanie generatorów i parametru key do sortowania
import operator
import timeit
import numpy as np
NUMBER = 1000000
idx = 2
l = [
(11, 52, 83, 56, 32), (61, 20, 40, 19, 230), (93, 72, 11, 67, 76),
(144, 22, 1, 99, 9), (91, 75, 101, 5, 78), (56, 43, 69, 24, 51)
]
def sort_by_idx():
sorted_l = []
l_idx_elements = [l_elem[idx] for l_elem in l]
for l_idx_elem in sorted(l_idx_elements):
for l_elem in l:
if l_idx_elem == l_elem[idx]:
sorted_l.append(l_elem)
continue
return sorted_l
setup = f'''
import operator
idx = {idx}
l = {l}
'''
assert sort_by_idx() == sorted(l, key=operator.itemgetter(idx))
print(np.mean(timeit.repeat(sort_by_idx, repeat=5, number=NUMBER))) # 2.41 s
print(np.mean(timeit.repeat('sorted(l, key=operator.itemgetter(idx))', setup=setup, repeat=5, number=NUMBER))) # 0.37 s2. Optymalizacja pętli - List Comprehensions
import timeit
from typing import List
import numpy as np
NUMBER = 1000000
adresses = ['PIOTRowo 2', 'Półwiejska 4', 'serafitek 1', 'Marii Skłodowskie-Curie 5', 'POLANKA 13', 'Jeleniogórska 51/14', 'Grunwaldzka 222']
def for_loop() -> List[str]:
streets = []
for adress in adresses:
street_name = ' '.join(adress.split(' ')[:-1])
street_name_uppercase = street_name.upper()
streets.append(street_name_uppercase)
return streets
def list_comprehension() -> List[str]:
return [' '.join(adress.split(' ')[:-1]).upper() for adress in adresses]
print(np.mean(timeit.repeat(for_loop, repeat=5, number=NUMBER))) # 2.80 s
print(np.mean(timeit.repeat(list_comprehension, repeat=5, number=NUMBER))) # 2.69 s3. Operacje na zestawach (ang. Set Operations)
W języku Python operacje na zestawach (ang. sets) są często szybsze niż operacje na listach, ze względu na przechowywanie elementów w postaci tablic haszów (ang. hash tables), które są efektywnie przechowywane w pamięci, a odczyt wartości jest stały O(1) bez względu na ilość elementów. Warto zatem wykorzystywać je w sytuacjach, gdy kolejność elementów jest nieistotna. Najczęściej wykorzystywane operacje na zestawach to:
- unia (ang. union)
- przecięcie (ang. intersection)
- różnica (ang. difference)
import timeit
from typing import List
import numpy as np
NUMBER = 10
l1 = list(range(100,100100))
l2 = list(range(100000))
def lists_union() -> List[int]:
union = l2.copy()
for l_elem in l1:
if l_elem not in union:
union.append(l_elem)
return union
def lists_intersection() -> List[int]:
intersection = []
for l_elem in l1:
if l_elem in l2:
intersection.append(l_elem)
return intersection
def lists_difference() -> List[int]:
difference = []
for l_elem in l1:
if l_elem not in l2:
difference.append(l_elem)
return difference
setup = f'''
l1 = {l1}
l2 = {l2}
'''
# union
assert sorted(set(l1).union(set(l2))) == sorted(lists_union())
print(np.mean(timeit.repeat('set(l1) | set(l2)', setup=setup, repeat=5, number=NUMBER))) # 0.06 s
print(np.mean(timeit.repeat('set(l1).union(set(l2))', setup=setup, repeat=5, number=NUMBER))) # 0.05 s
print(np.mean(timeit.repeat(lists_union, repeat=5, number=NUMBER))) # 4.51 s
# intersection
assert sorted(set(l1).intersection(set(l2))) == sorted(lists_intersection())
print(np.mean(timeit.repeat('set(l1) & set(l2)', setup=setup, repeat=5, number=NUMBER))) # 0.05 s
print(np.mean(timeit.repeat('set(l1).intersection(set(l2))', setup=setup, repeat=5, number=NUMBER))) # 0.05 s
print(np.mean(timeit.repeat(lists_intersection, repeat=5, number=NUMBER))) # 5.35 s
# difference
assert sorted(set(l1).difference(set(l2))) == sorted(lists_difference())
print(np.mean(timeit.repeat('set(l1) | set(l2)', setup=setup, repeat=5, number=NUMBER))) # 0.08 s
print(np.mean(timeit.repeat('set(l1).difference(set(l2))', setup=setup, repeat=5, number=NUMBER))) # 0.04 s
print(np.mean(timeit.repeat(lists_difference, repeat=5, number=NUMBER))) # 5.58 s4. Unikanie korzystania ze zmiennych globalnych
import timeit
from typing import List
import numpy as np
NUMBER = 100
global_multiplier = 3
l = list(range(1000000))
def func_with_global(l: List[int]):
global global_multiplier
func_sum = 0
for l_elem in l:
func_sum += l_elem**global_multiplier
return func_sum
def func_without_global(l: List[int], multiplier: int):
func_sum = 0
for l_elem in l:
func_sum += l_elem**multiplier
return func_sum
setup = f'''
from __main__ import func_with_global, func_without_global
global_multiplier = 3
l = {l}
'''
print(np.mean(timeit.repeat(stmt='func_with_global(l)', setup=setup, repeat=5, number=NUMBER))) # 25.07 s
print(np.mean(timeit.repeat(stmt='func_without_global(l, global_multiplier)', setup=setup, repeat=5, number=NUMBER))) # 24.08 s5. Wykorzystanie zewnętrznych bibliotek i pakietów
Niektóre operacje można wykonać szybciej, korzystając z zewnętrznych bibliotek i pakietów, które są zaimplementowane w języku C lub C++. Warto zatem zastanowić się, czy nie ma gotowych rozwiązań, które mogą nam pomóc w rozwiązaniu problemu. Jednym z przykładów jest pakiet NumPy, zawierający wiele funkcji, które są wydajniejsze niż te wbudowane w język Python.import timeit
import numpy as np
NUMBER = 1000
setup = '''
import numpy as np
l = list(range(100000))
'''
print(np.mean(timeit.repeat('list(map(lambda x: x**2, l))', setup=setup, repeat=5, number=NUMBER))) # 28.59 s
print(np.mean(timeit.repeat('np.power(l, 2)', setup=setup, repeat=5, number=NUMBER))) # 3.86 s6. Wykorzystanie wbudowanych funkcji
Dostępne wbudowane funkcje w języku Python można znaleźć w dokumentacji: https://docs.python.org/3/library/functions.html.import timeit
from typing import List
import numpy as np
NUMBER = 100
l = list(range(1000000))
def sum_list_elements(l: List[int]):
s = 0
for l_elem in l:
s += l_elem
return s
assert sum(l) == sum_list_elements(l)
setup = f'''
from __main__ import sum_list_elements
l = {l}
'''
print(np.mean(timeit.repeat('sum_list_elements(l)', setup=setup, repeat=5, number=NUMBER))) # 3.35 s
print(np.mean(timeit.repeat('sum(l)', setup=setup, repeat=5, number=NUMBER))) # 0.71 s7. Optymalizacja przetwarzania danych typu String
Wszystkie dostępne operatory na danych typu String są opisane w dokumentacji: https://docs.python.org/3/library/stdtypes.html#string-methods.import timeit
from typing import List
import numpy as np
NUMBER = 100
files = [
str(np.random.randint(0, 1000)).zfill(3) +\
np.random.choice(['.png', '.jpg', '.txt', '.yaml']) for _ in range(1000000)
]
def find_files(files: List[str], extension: str) -> List[str]:
selected_files = []
for f in files:
file_extension = f.split('.')[-1]
if file_extension == extension:
selected_files.append(f)
return selected_files
def find_files_endswith(files: List[str], extension: str) -> List[str]:
selected_files = []
for f in files:
if f.endswith(extension):
selected_files.append(f)
return selected_files
assert find_files_endswith(files, 'yaml') == find_files(files, 'yaml')
setup = f'''
from __main__ import find_files, find_files_endswith
files = {files}
extension = "yaml"
'''
print(np.mean(timeit.repeat('find_files(files, extension)', setup=setup, repeat=5, number=NUMBER))) # 17.06 s
print(np.mean(timeit.repeat('find_files_endswith(files, extension)', setup=setup, repeat=5, number=NUMBER))) # 8.92 s8. Optymalizacja bloków warunkowych (ang. If statements)
import timeit
NUMBER = 100000000
print(np.mean(timeit.repeat('if a != None: a += 1', setup='a = None', repeat=5, number=NUMBER))) # 2.17 s
print(np.mean(timeit.repeat('if a is not None: a += 1', setup='a = None', repeat=5, number=NUMBER))) # 1.31 s9. Cython - kompilacja kodu języka Python
Język Python jest językiem interpretowanym, co oznacza, że kod źródłowy jest przetwarzany w czasie wykonania programu. W przypadku dużych programów, w których często wykonywane są operacje na dużych zbiorach danych, może to spowodować znaczne spowolnienie działania programu. W celu optymalizacji takich programów, można wykorzystać język programowania o typie statycznym, który pozwala na kompilację kodu źródłowego do kodu maszynowego. Jednym z takich języków jest Cython.Zadanie 2. Dokonaj optymalizacji kodu źródłowego przedstawionego w zadaniu 1 korzystając z wyżej wymienionych metod. Wykorzystując narzędzia do profilowania, porównaj wydajność przygotowanego rozwiązania z oryginalnym kodem źródłowym.
Profilowanie metod uczenia maszynowego
Kod źródłowy
from typing import Tuple
import numpy as np
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
@profile
def get_train_test_data() -> Tuple[np.ndarray, np.ndarray, np.ndarray, np.ndarray]:
X, y = load_iris(return_X_y=True)
##### TODO Student #####
# Podziel dane na zbiór treningowy i testowy w stosunku 70%-30%
X_train, X_test, y_train, y_test = None, None, None, None
########################
return X_train, X_test, y_train, y_test
@profile
def main():
##### TODO Student #####
# Dokonaj inicjalizacji klasyfikatora z biblioteki scikit-learn
clf = KNeighborsClassifier()
########################
X_train, X_test, y_train, y_test = get_train_test_data()
##### TODO Student #####
# Wytrenuj klasyfikator z wykorzystaniem zbioru treningowego
# Dokonaj ewaluacji na zbiorze testowym
# Wykonaj klasyfikację pojedynczej próbki ze zbioru testowego
for _ in range(100):
pass
# Wykonaj klasyfikację dla grupy 16 próbek ze zbioru testowego (ang. batch prediction)
for _ in range(100):
pass
########################
if __name__ == '__main__':
main()Zadanie 3. Uzupełnij powyższy kod źródłowy i dokonaj profilowania klasyfikatora na zbiorze danych iris wykorzystując pakiety line_profiler oraz memory_profiler. Porównaj wydajność klasyfikatorów z biblioteki scikit-learn z wykorzystaniem domyślnych parametrów. Zbadaj, które z nich są najbardziej wydajne pod względem czasu i pamięci. Przygotuj wykres słupkowy obrazujący czas predykcji dla 1 i 16 próbek ze zbioru testowego dla klasyfikatorów:
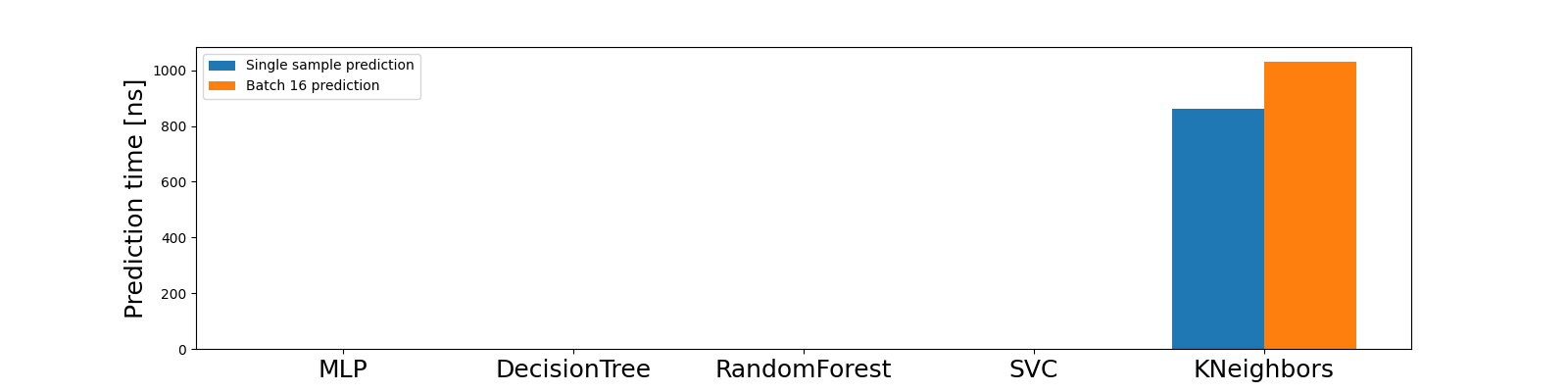
Wskazówki dotyczące optymalizacji modeli uczenia maszynowego z pakietu scikit-learn są opisane w dokumentacji biblioteki, w artykule How to optimize for speed.
Profilowanie algorytmów opartych o sieci neuronowe
Ostatnia część instrukcji wymaga wykorzystania GPU i w tym celu należy skorzystać z platformy Google Colab. Przygotowany notebooka jest dostępny pod linkiem 02 - Profilowanie algorytmów opartych o sieci neuronowe.
