11 - TinyML: Keyword spotting
Systemy Wbudowane i Przetwarzanie Brzegowe
Politechnika Poznańska, Instytut Robotyki i Inteligencji Maszynowej
![]()
Ćwiczenie laboratoryjne 11: Keyword Spotting
Powrót do spisu treści ćwiczeń laboratoryjnych
Wstęp
W czasie zajęć wykorzystamy platformę Edge Impulse do stworzenia modelu klasyfikacji, który będzie rozpoznawał wydarzenia dźwiękowe takie jak słowa kluczowe. W tym celu wykorzystamy dookólny wbudowany mikrofon MP34DT05 dostępny w Arduino Nano 33 BLE Sense oraz model klasyfikacji dźwięku. Przygotowane laboratorium jest oparte o instrukcję Responding to your voice, dostępną w dokumentacji platformy Edge Impulse.
Edge Impulse
Platforma Edge Impulse jest środowiskiem do tworzenia i wdrażania aplikacji z wykorzystaniem uczenia maszynowego na urządzeniach brzegowych i mikrokontrolerach. Umożliwia akwizycję danych z szerokiej gamy czujników, ich analizę, a następnie przetwarzanie przy wykorzystaniu algorytmów klasyfikacji, regresji, detekcji anomalii lub wykrywania obiektów. Środowisko Edge Impulse umożliwia również przygotowanie modeli uczenia maszynowego z wykorzystaniem instancji chmurowych, a także bezpośrednio wspiera ich wdrażanie na docelowe urządzenia. Wszystkie wspierane przez platformę urządzenia można znaleźć w dokumentacji.
.svg)
Aktywacja środowiska i podłączenie urządzenia
Szczegółowa instrukcja instalacji zależności oraz podłączenia urządzenia jest dostępna tutaj. Natomiast wymagane kroki zostały opisane poniżej.
Instalacja zależności (komputery w laboratorium nie wymagają realizacji tego kroku).
Instalacja pakietu screen (jedynie na urządzeniach Linux)
sudo apt install screen
Połączenie z Edge Impulse
Połącz urządzenie przy pomocy przewodu micro-USB z komputerem. Następnie poprzez podwójne naciśnięcie przycisku reset uruchom bootloader. Pomarańczowa dioda na płytce powinna zacząć pulsować.
Zaktualizuj oprogramowanie sprzętowe (ang. firmware) urządzenia (do realizacji tylko raz w przypadku własnego urządzenia, mikrokontrolery w laboratorium posiadają aktualne oprogramowanie).
Pobierz i wypakuj najnowszą wersję oprogramowania sprzętowego.
Uruchom odpowiedni skrypt w zależności od wykorzystywanego systemu operacyjnego.
Po ukończeniu procesu aktualizacji zresetuj urządzenie w celu uruchomienia nowego oprogramowania.
Zaloguj się do środowiska Edge Impulse za pomocą poniższego polecenia i wybierz odpowiedni projekt.
edge-impulse-daemon
- Korzystając z przeglądarki internetowej przejdź do strony Edge Impulse, zaloguj się do swojego konta i w panelu Devices sprawdź czy urządzenie zostało poprawnie połączone.

Zbieranie danych
W serwisie Edge Impulse do zbierania danych wykorzystywana jest zakładka Data acquisition, a jej widok wraz z zaznaczonymi najważniejszymi elementami został przedstawiony poniżej. Dane można przygotować na dwa sposoby - zbierając je bezpośrednio z urządzenia lub przesyłając w odpowiednim formacie (i z odpowiednim oznaczeniem) poprzez zakładkę Upload data. W czasie laboratorium wykorzystamy pierwszą opcję do zbierania słów kluczowych oraz drugą do dodania pozostałych dźwięków i szumu.
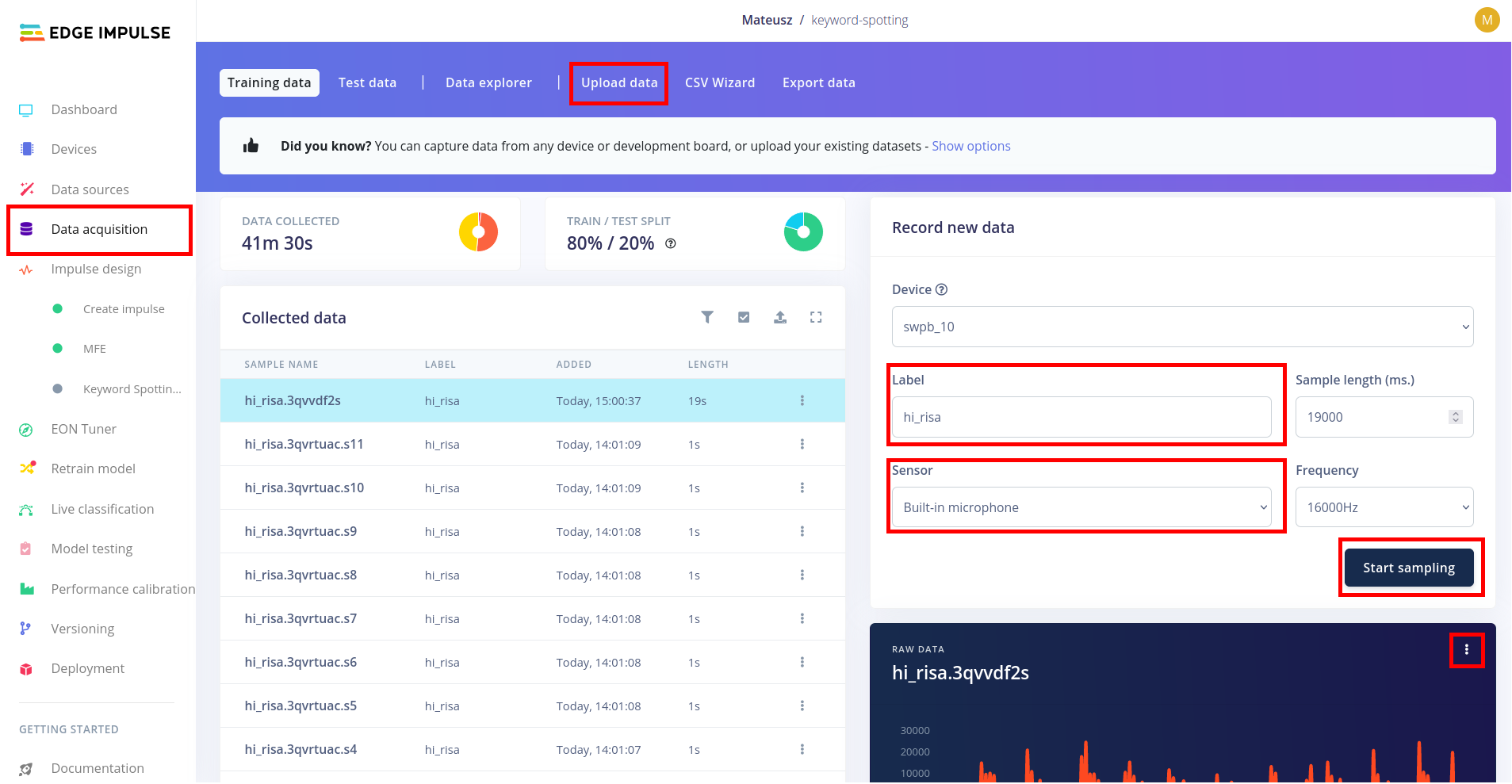
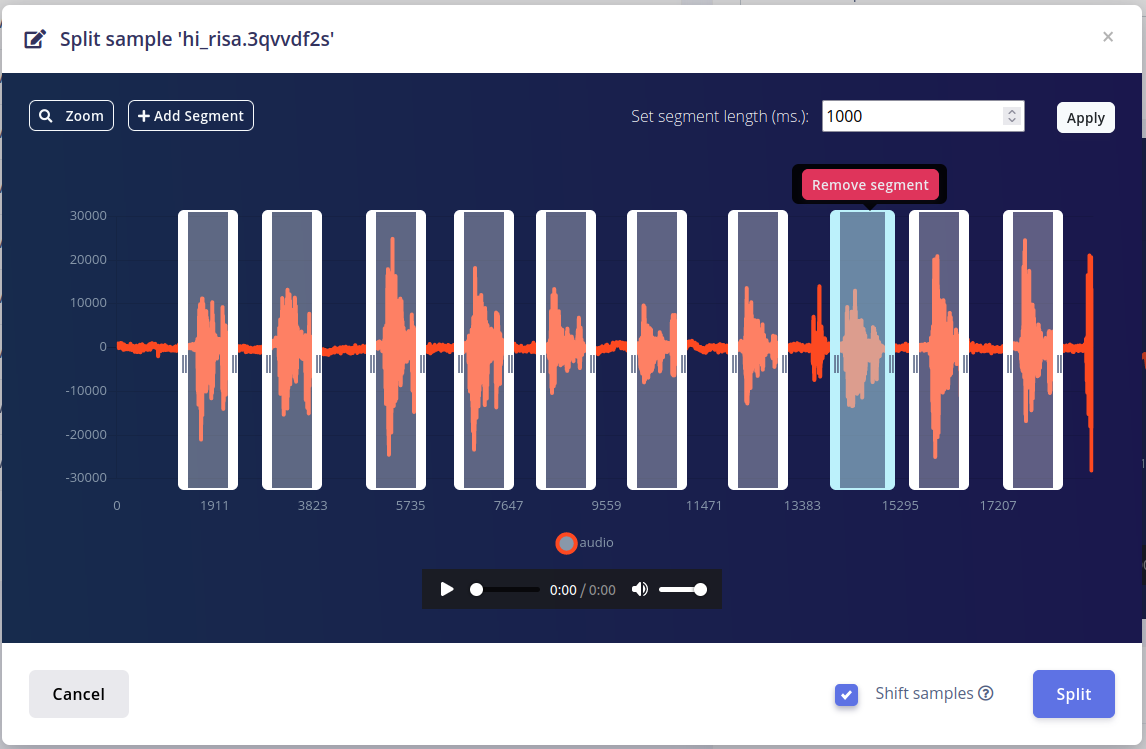
- Słowo kluczowe - w celu zebrania nowych danych należy wybrać odpowiednie urządzenie, ustalić etykietę danych oraz wybrać sensor - w tym przypadku wbudowany mikrofon. Następnie należy nacisnąć przycisk Start sampling i wypowiedzieć słowa kluczowe. Po zakończeniu nagrany dźwięk można podzielić na mniejsze fragmenty, zawierające pojedyncze wystąpienie słowa kluczowego. W tym celu z menu konteksowego wykresu przedstawiającego nagraną próbkę wybieramy Split sample. Następnie należy zaznaczyć odpowiednie fragmenty, zweryfikować czy zawierają poprawne słowa kluczowe i nacisnąć przycisk Split. Aby wyniki klasyfikacji słowa kluczowego przez algorytm były jak najbardziej dokładne, należy wygenerować przynajmniej 50-100 pojedynczych próbek.
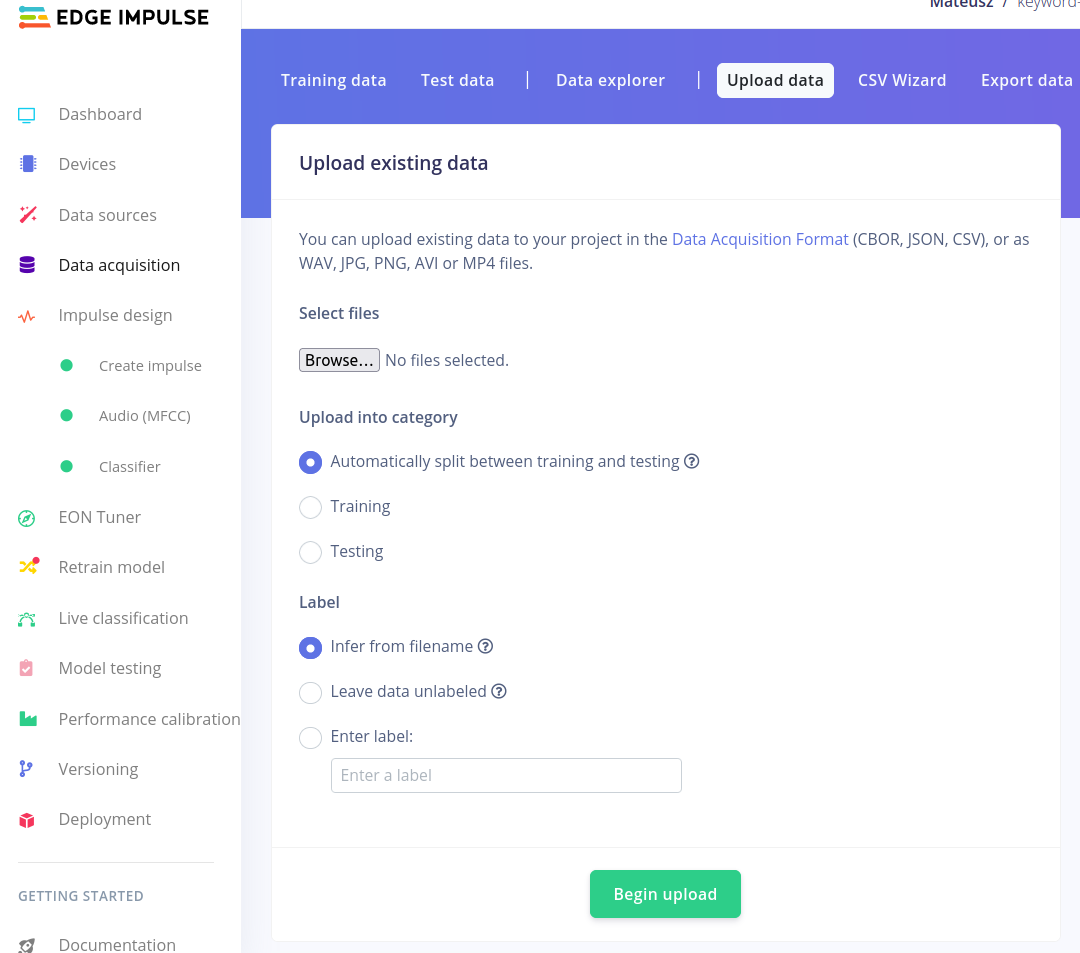
- Pozostałe dźwięki - szum oraz nieznane wyrazy - w celu zaoszczędzenia czasu wykorzystamy dane zebrane przez innych użytkowników oraz Edge Impulse dostępne w zbiorze danych keywords dataset. W celu ich dodania należy pobrać i wypakować zbiór danych, a następnie w zakładce Upload data poprzez przycisk Browse wybrać katalog noise i nacisnąć przycisk Begin upload. Powtórzyć czynność dla danych z katalogu unknown.
Zadanie 1. Wymśl swoje własne słowo kluczowe i zbierz około 50-100 pojedynczych próbek zawieracjących je. Postaraj się, aby słowo kluczowe było charakterystyczne, zawierało od 2 do 4 sylab oraz mieściło się w 1-sekundowym oknie (zalecane). Po przygotowaniu danych, podziel je pomiędzy zbiór treningowy i testowy. Dodaj do przygotowanych danych nagrania szumu oraz nieznanych wyrazów tak jak to zostało opisane w powyższym punkcie.
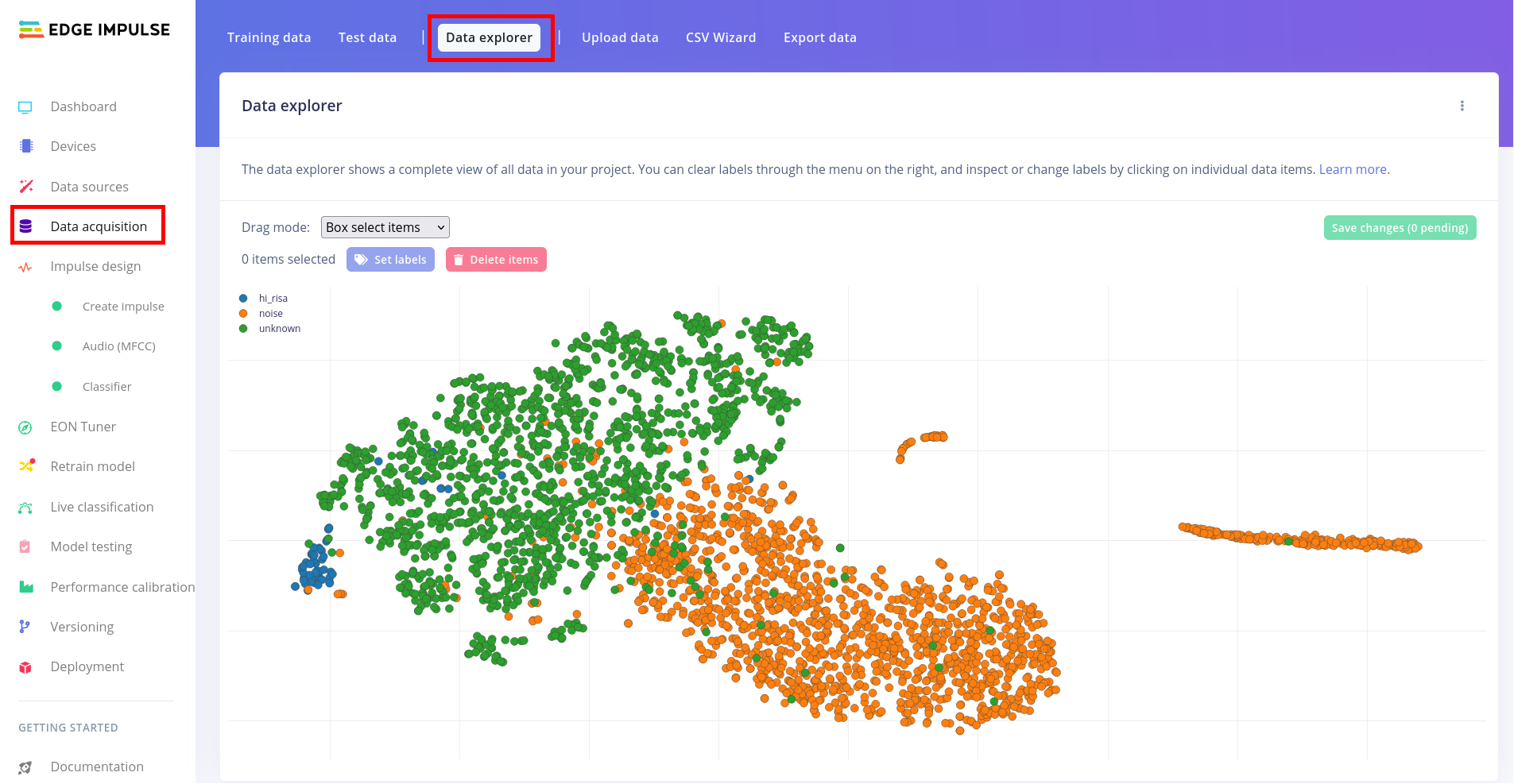
Analiza zebranych danych
Analizy zebranych danych można dokonać w panelu Data explorer dostępnym w zakładce Data acquisition. Początkowo dostępna będzie jedynie opcja wykorzystania pretrenowanego modelu do wygenerowania cech dla każdej próbki, a następnie przy wykorzystaniu jednej z metod redukcji wymiarowości możliwe jest wyświetlenie danych w 2-wymiarowej przestrzeni. Po przygotowaniu klasyfikatora (następne kroki) możliwy jest powrót do zadania analizy danych i wykorzystanie cech wyznaczonych przez klasyfikator lub metodę przetwarzania wstępnego do wygenerowania nowego zestawu cech oraz wizualizacji.
Tworzenie i ewaluacja klasyfikatora
W środowisku Edge Impulse modele wraz z algorytmami przetwarzania wstepnego są znane pod nazwą Impulse. W zakładce Impulse design należy wybrać Create impulse i wypełnić bloki zgodnie z poniższym schematem. W przedstawionym przykładzie dane z wbudowanego mikrofonu będą zbierane w okna o długości 1000 ms z przesunięciem co 250 ms (ang. overlap). Następnie z wykorzystaniem algorytmu Mel Frequency Cepstral Coefficients (MFCC) zostaną wyznaczone cechy charakterystyczne dla każdego okna. Cechy te są wejściem wybranego klasyfikatora, którego wyjściem jest jedna z trzech klas - słowo kluczowe, szum lub nieznany wyraz.
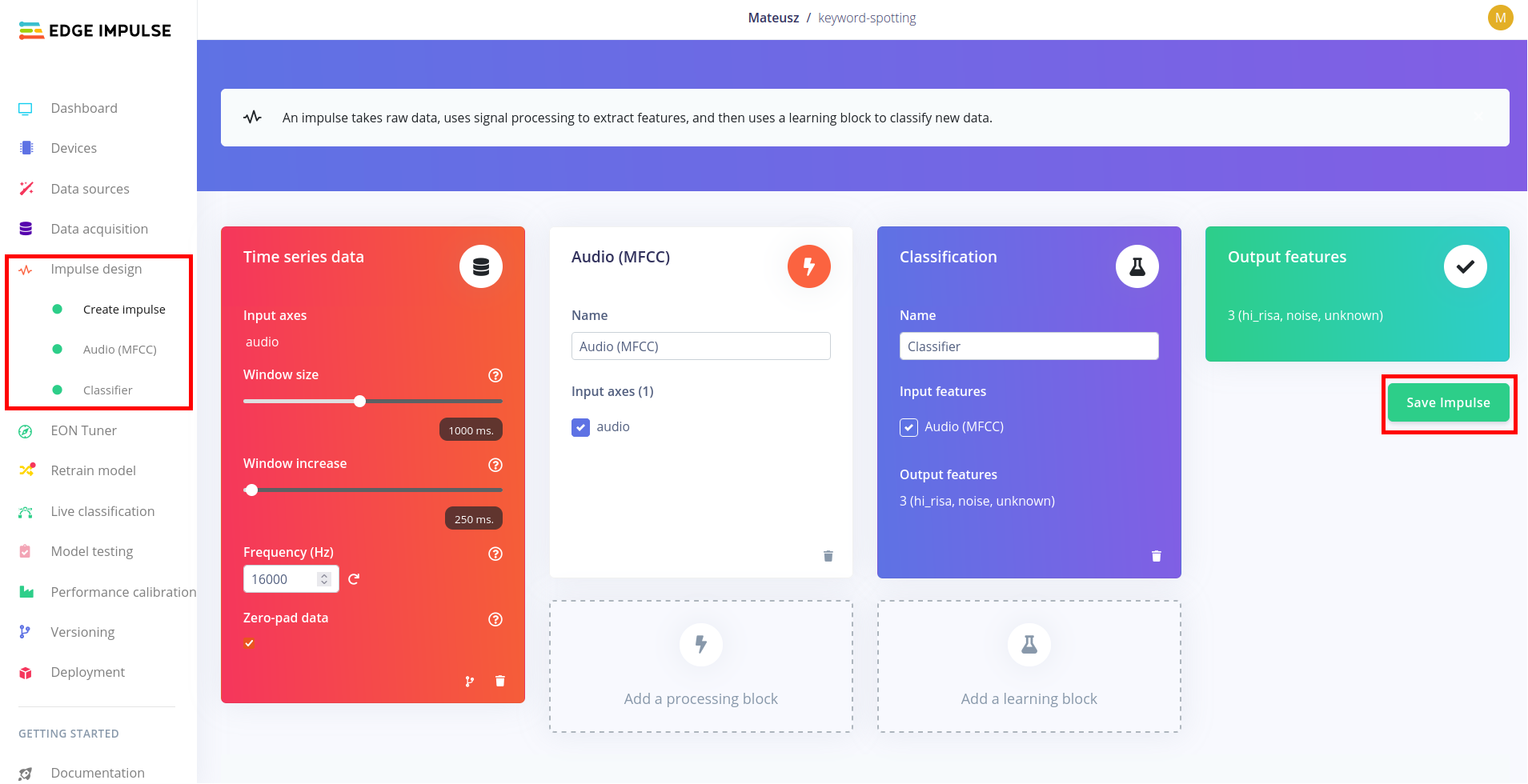
W zakładce Audio (MFCC) można dostosować parametry przetwarzania wstępnego (do celów laboratorium mogą pozostać domyślne wartości). W zakładce Classifier należy wybrać odpowiedni klasyfikator, ustalić liczbę epok treningu oraz zdefiniować pozostałe hiperparametry. Edge Impulse udostępnia ograniczone środowisko chmurowe do treningu modeli, z którego możemy skorzystać do przygotowania klasyfikatora. W tym celu należy rozpocząć trening przyciskiem Start training, który znajduje się pod konfiguracją sieci neuronowej.
Po zakończeniu treningu istnieje możliwość optymaplizacji modelu z wykorzystaniem narzędzia EON Tuner. Jest to narzędzie AutoML pozwalające na automatyczne dobieranie najlepszych hiperparametrów dla modelu, ale w odróżnieniu od innych, podobnych rozwiązań uwzględnia ono również parametry przetwarzania wstępnego oraz ograniczenia aplikacyjne oraz sprzętowe docelowego urządzania.
Przygotowany Impulse można przetestować na dwa sposoby:
- Korzystając z zakładki Model testing, w której klasyfikacji poddane zostaną próbki ze zbioru testowego.
- Wykorzystując opcję Live classification, która rejestruję nową próbkę dźwięku w czasie rzeczywistym i wyświetla wyniki klasyfikacji dla zdefiniowanych okien czasowych.
Wdrożenie modelu na urządzenie docelowe
W ceku uruchomienia modelu na urządzeniu docelowym należy w zakładce Deployment i sekcji Create library wybrać Arduino library. Następnie wykorzystać klasyfikator w formacie INT8 i przygotować bibliotekę poprzez naciśnięcie przycisku Build.

Po pobraniu biblioteki należy dodać ją do Arduino IDE poprzez Sketch -> Include library -> Add .zip library.... Skrypty do obsługi przygotowanego modelu znajdują się w File -> Examples -> <Nazwa Projektu>_inferencing.
Zadanie 2. Korzystając z przykładu dostępnego w katalogu File -> Examples -> <Nazwa Projektu>_inferencing -> nano_ble33_sense -> nano_ble33_sense_microphone przetestuj działanie przygotowanego modelu. Dodatkowo dodaj do urządzenia:
- diodę LED, która będzie sygnalizować wykrycie słowa kluczowego,
- obsługę modułu BLE (Bluetooth Low Energy) w celu przesyłania informacji o wykryciu słowa kluczowego do aplikacji mobilnej.
Zadanie 3. Powtórz zadanie dla przykładu wykorzystującego ciągłą inferencję. W przypadku wystąpienia kodu błędu, jego opis można sprawdzić w dokumentacji.
